sovit3折腾实录与教程(1)本地篇
在此感谢我兄弟@IAW_PRC提供的一些技术支持
过程实在太长太折磨,再加上本人上学,时间不多,所以这篇东西写的不会像之前那么详细
免责声明
在开始阅读前,您需要知道:
截至目前,Ai一直是版权重灾区,如果阁下因为不正当使用Ai所造成的侵权与纠纷,需要您本人承担,与作者,也就是我无关
起因:
我是一个sb二次元,天天听日语歌几年没碰华语的那种
当然不只是因为华语乐坛近几年来确实不行
更多的是我喜欢非母语带来的那种 有些听不懂的神秘感?
总之,在刷夜に駆ける的各种翻唱的时候
AI东雪莲吸引了我的注意
抛开政治色彩不谈,唱的甚至比本人还好听 (ai不夹)
刚好换了新显卡不久,打算折腾一下AI有关的东西
前期准备
你要让AI学习一个人的声音,当然得先有他的声音
如果是Vtuber啥的,把录播下下来自动切片就好
这里是我兄弟的,我选择了用我兄弟打游戏时候的语音,然后Au里手动裁剪
因为语音有别人的,只能自己辨认
用了一个多小时,裁剪出100多条
这里得说一下,切片当然是越多越好,但是
质量>数量
个人认为如果是说话至少得有70条以上的语音吧
唱歌的话可能要1000条,并且最好有本人唱歌的录音,要不然可能高音上不去低音下不来
每条在3-4s,不用太长,要求无背景音,无混响,无其他人说话的声音
如果声音很杂我建议想办法处理一下
分离人声和背景音我最推荐的就是UVR5
这个百度一下就有,用起来不难,不细说了
开始之前的废话
本人配置:
CPU:i7-11700K
MEM:32G 3200MHz XMP
GPU:RTX3070Ti 8G
别的不写了,重点其实就在GPU上,有CUDA真的能让你事半功倍
如果你是A卡用户或者没有CUDA核心的显卡,亦或者很老的卡,那我都强烈建议你去Colab篇
如果你不想折腾,也只是想试试看,也推荐去Colab
什么3090 4090 A100的,显存还12G以上的话,那本地肯定快
这边实测,免费版Colab速度不如我的3070Ti
同为1000steps,Colab用了大概半小时
我这本地就十多分钟不到
A卡似乎RX5000系列RDNA2对于深度学习有奇效,甚至可能超过30系,据说是stable diffusion和vits有加成
但如果你是A卡用户我能想到的唯一办法就是去Linux,并且使用ROCM版本的Pytorch
也就是
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/rocm5.2
如果你是A卡装完这个之后请无视掉下面的torch安装
噩梦开始
去这里Clone一下库文件
除非你显存>8G,不然我都建议你选32K的分支
我这里用PyCharm打开,构建一个虚拟环境
如果你电脑环境比较干净,不用PyCharm啥的也是可以的,因为之前折腾Arcaea的时候环境很杂
然后把之前你的切片搞个名字,可以是说话人的拼音啥的,放到一个文件夹,并放到这个项目的dataset_raw里,文件架构应该是
../so-vits-svc-32k/dataset_raw/你说话人的名字/xxx1.wav
../so-vits-svc-32k/dataset_raw/你说话人的名字/xxx2.wav
...
环境配置
给一个忠告:无论是环境还是库,不要追求新的,requirements.txt给啥你就装啥,报错就降一个大版本,比如你装了0.10.0的librosa,报错了,降一个大版本到0.9.2,还不行就降到0.8.1
好,到了你需要迈过的第一个坎了
Sovits不像当时NovelAi这么火爆,成本也比NovelAI高,一键启动包什么的,似乎训练出来模型会有别人的味道(?)
不管怎么说,享受折腾的过程也是种乐趣
Sovits对环境的要求还是很复杂的
当然我见识短浅没见过什么更复杂的大工程也是真的
据说Python版本大于3.10会存在numpy1.19.2无法安装的问题
我是确实遇上了,不是无法安装而是安装无法使用
所以我个人建议使用3.9版本的Python
先打开requirements.txt,把
torch==1.10.0+cu113
torchaudio==0.10.0+cu113
这两行删掉
然后用这串东西下载环境
pip install -r requirements.txt
如果你用PyCharm打开它会自动读取requirements.txt里的内容让你补全环境
我这里补全了大部分,剩下一个失败了:
numpy==1.19.2
这里就不得不提一下国内源的问题,numpy版本太奇妙或许是,换回原来的源就好
我这里是
pip install -i https://pypi.python.org/simple numpy==1.19.2
这里给大家排个雷,matplotlib在上面应该会自动安装
如果你是1.19.2的numpy,那会提示
Matplotlib requires numpy>=1.20; you have 1.19.2
手动把matpotlib降级到3.6.3即可,也就是
pip uninstall matpotlib
pip install matpotlib==3.6.3
然后是torch的问题,这才是这个项目的核心
打开你的cmd (草妈的)
输入
nvidia-smi.exe
看看你的CUDA版本,我这里是12.0
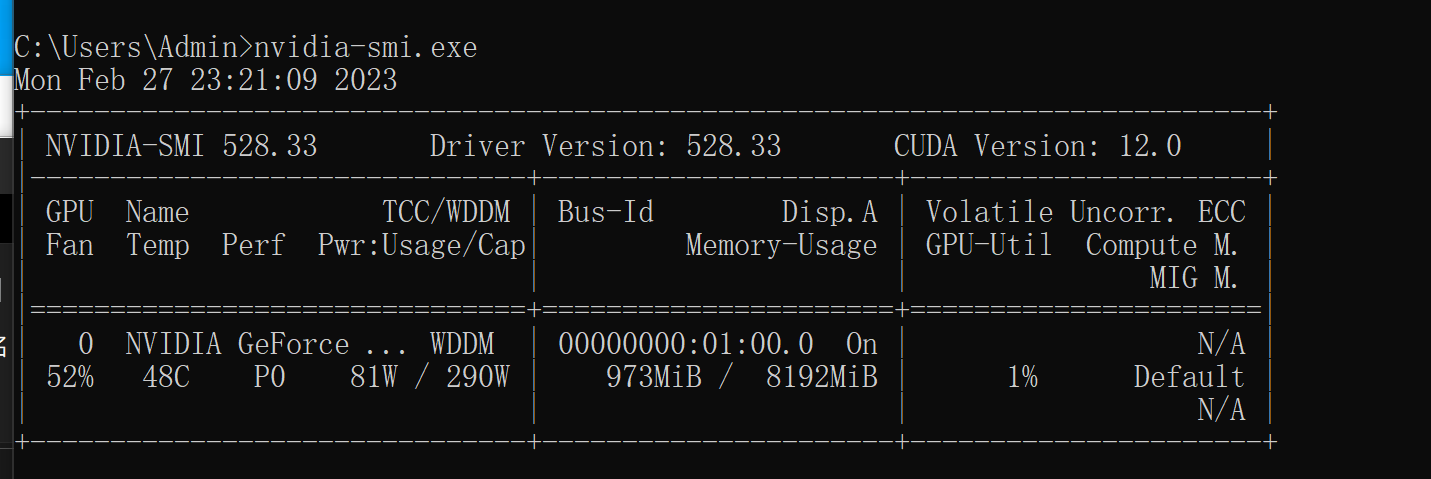
虽然理论来说Pytorch最高只支持11.7
但我这没问题
总之,去下一个和你CUDA版本对应的的Pytorch,如果你像我一样是12.0,那就下11.7版本就好
我这里是
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
然后,去这里,下载和你cuda版本对应的kit,并安装(要等挺久的,文件也很大)
开始操作
然后下载三个预训练模型文件
放到hubert目录下
放到logs/32k目录下
总之,以上都没问题的话,确保你的文件夹已经放在dataset_raw中,并继续
数据预处理
1.重采样
在你的项目文件夹打开终端,并输入
python resample.py
这一步是把你的wav重采样成32khz
如果你报错提示缺少librosa,那就来一条
pip install librosa==0.8.1
试过新版本会报错,所以这个可以
2.生成配置文件等
python preprocess_flist_config.py
3.生成hubert与f0
python preprocess_hubert_f0.py
如果都按照上面的来,这三步基本不会有问题
调节配置
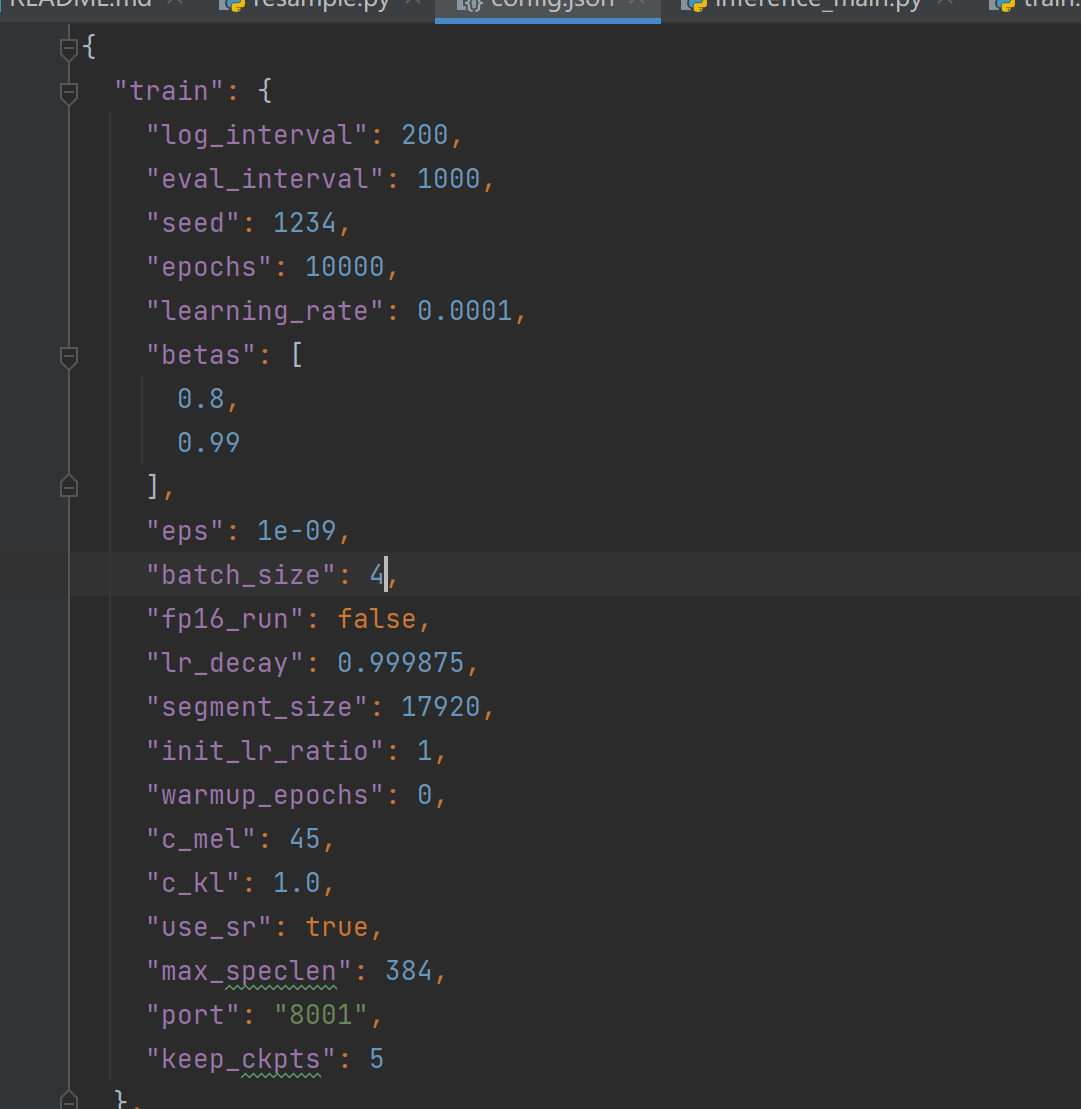
一般来说我们贫民的小显存,.../configs/config.json里给的默认12的batch_size,百分百会爆显存
我8G在后台有点东西的时候给6都会爆显存,并且为了发挥你显卡的最佳性能,batch_size最好是2的倍数
如果你是30系以上,为了调用Tensor核心,最好能4的倍数
如果你给4都爆显存还是建议是去Colab了,batch_size太小模型可能会不收敛,出来效果也会有影响
我这里就给4了
开始训练
打开命令行,输入
python train.py -c configs/config.json -m 32k
如果这个时候报错了,提示缺少TensorBoard,那就
pip install tensorboard
这个倒是不需要什么版本(目前没见有问题)
出现如下命令行就代表训练正常进行了

默认每1000次保存一个记录点,如果想停止训练按Ctrl+C即可
下一次训练在输入一样的命令程序会自动读取存档点继续训练
观察训练过程确定收敛进度
在训练的时候新开一个命令行,输入
tensorboard ----logdir logs/32k --port 8080
端口如果占用了可以改
然后浏览器打开http://localhost:8080/
点上面scalars,并把learning rate和loss展开,loss翻到第二页
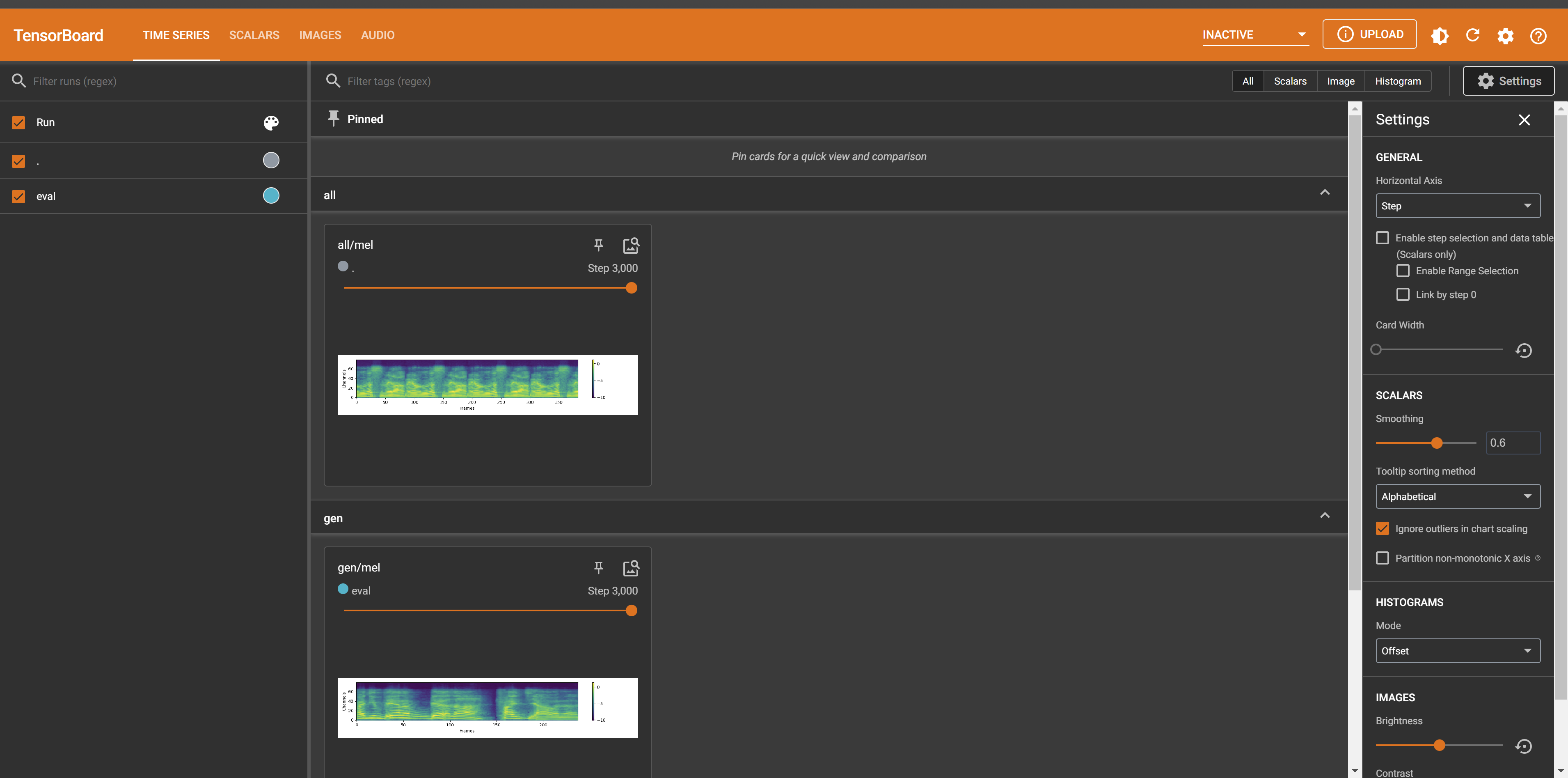
主要看learning_rate和loss最后面三个图表,也就是
g/kl g/mel g/total
learning_rate不断下降,且下降幅度放缓
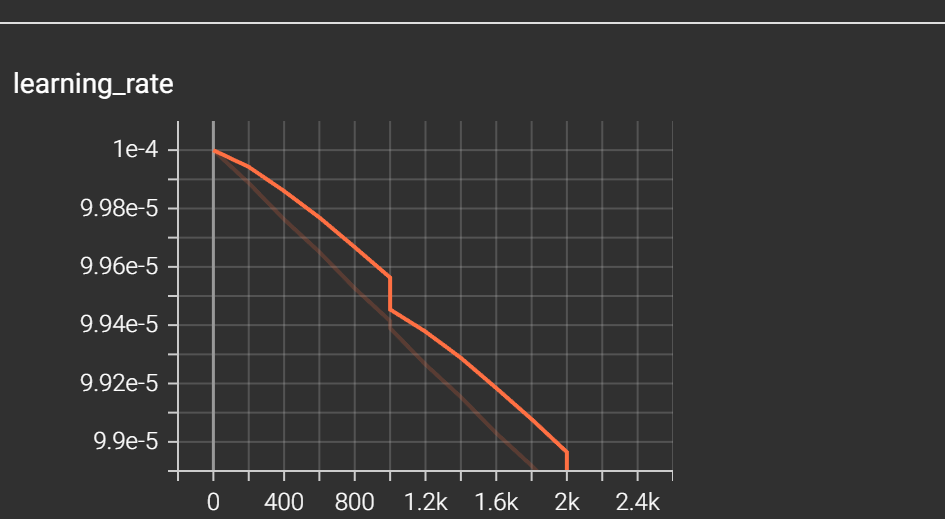
g/kl g/mel g/total不断下降,且几乎与X轴平行,下降放缓
就代表模型基本收敛了,这个时候再训练下去可能会过拟合,模型会废
确定收敛了就可以停止训练,并进行下一步了
推理
把你要转换的文件放在.../raw/xxx.wav
可以是歌曲的纯人声,可以是说话声音
然后打开.../inference_main.py
重点改model_path,clean_names,trans,spk_list这几个
model_path改成你训练出最新模型的路径
注意:推理所需要的是G_开头的模型,而不是D_开头的
clean_names改为你raw文件夹中放的wav的文件名,无需.wav结尾
trans为变调,根据实际来调,男模型唱女声大概需要-12~-16
spk_lisk为你说话人的名字,可以支持多个,用半角逗号隔开
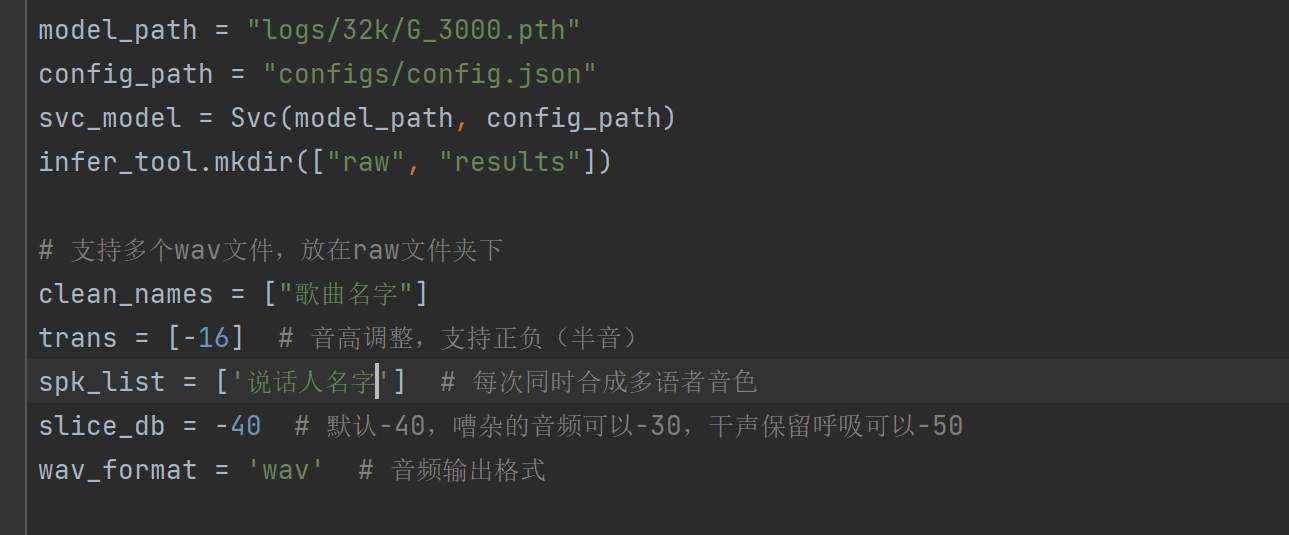
没啥问题就可以开始推理了
python inference_main.py
如果你推理报错,提示numpy版本太旧,请将pandas降级到1.4.4,也就是
pip uninstall pandas
pip install pandas==1.4.4
3.8更新:
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
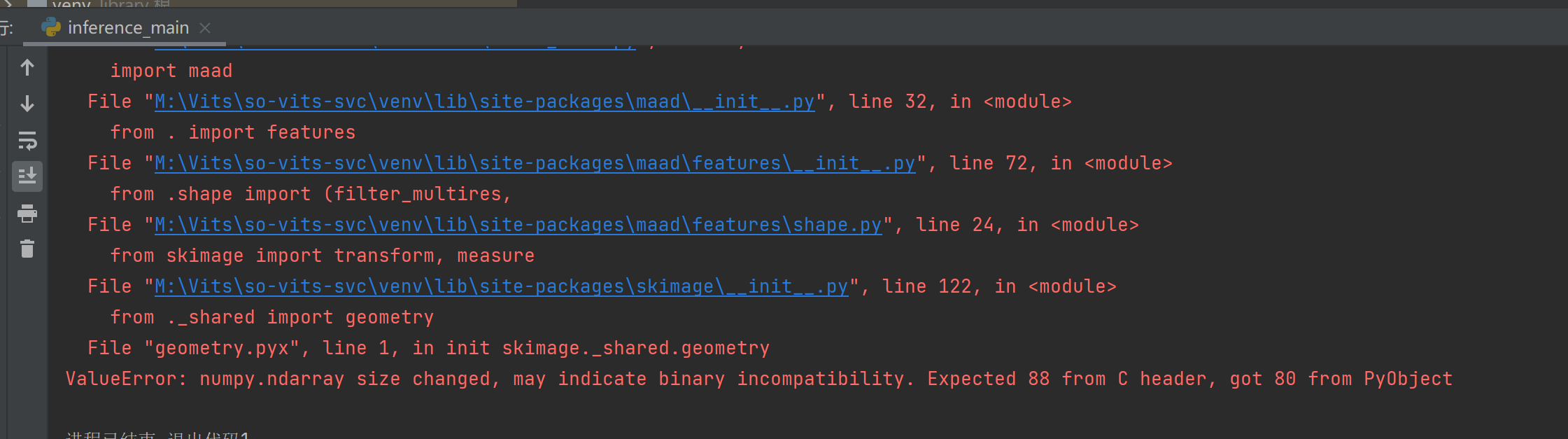
真是tmd神奇,用着用着就推理不了了
还好是虚拟环境,要是那些直接装在系统上的绝对会裂开
强烈建议用Conda, 去你妈的pip
摸索了一圈,我的解决方法是:降级scikit-image到0.19.3
pip uninstall scikit-image
pip install scikit-image==0.19.3
想不到吧tmd,你以为是numpy的问题,其实是scikit-image的锅
推理的话,歌曲不宜太长,特别是显存小的,很容易爆显存
建议裁开分开推理
当然你可以用CPU推理,但会非常非常慢(比GPU慢是肯定的)
大概一首歌3分钟,CPU就要推3分钟,GPU不爆显存的话就半分钟多
想要CPU推理的话
修改inference/infer_tool.py这个文件,在21行后面加一行
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
CPU推理我没有实操过,但如果报错了大概是需要装CPU版本的Pytorch吧(不确定,建议Google)
只要有Torch就行,是cuda还是CPU无所谓
推理结束后,你的成果就在…/results中了
至此,本地Sovits也就告一段落了
一些问题解答
batch_size
最前面的当属batch_size,网上只告诉你这个越大占显存也越大,却没告诉你batch_size对于模型和成果有着直接影响
batch_size是指在一次迭代中输入给模型的样本数量。在训练深度学习模型时,通常会将训练数据集分成多个batch,每个batch包含一定数量的样本。模型将会接收每个batch的样本作为输入,计算并更新模型的参数。这个过程称为一个epoch,通常需要多个epoch来训练一个模型。
(此回答来自ChatGPT)
显然,batch_size有一个最佳值可以训练出效果最好的模型
虽然理论来说,batch_size太大会翻车
但据我所知,除非你是80G的A100阵列,不然绝大多数情况下应该是达不到翻车的数值的
所以在不炸显存的情况下,可以暂且理解为batch_size越大越好
我看到有人问“啊为什么我的loss一直在波动没有收敛迹象的?”
那多半就是batch_size的锅
网上那些说batch_size给2 甚至1的那完全是 离大谱
特别是1,那意味着Ai会随机抽取样本进行学习,每次就一个样本
那能不能收敛完全就是看脸
为什么我想放在最前面写这个,正是因为我batch_size给到了4波动依然很大(已经超过10w steps)
但你要说batch_size太小真的不能用吗 倒也不是
毕竟样本还是样本,只能说你的模型大概永不会收敛
总之,显存小去Colab总不是一件坏事,干嘛要折腾自己电脑呢
Sovits3.0和Sovits4.0
测试过后发现Sovits4.0无论是训练还是推理显存占用都小了很多
同样是8G,Sovits4.0我甚至可以开到8的batch_size
但也有奇怪的情况
在我这,Sovits4.0在相同的steps下出来的效果远远不如3.0
在3.0中只需要1000steps就已经有贴近本人声线的感觉了
而4.0同样1000steps甚至2000steps,出来的结果也会带电
(以上是实测经历,不代表通用性,因为只是我一个人的实验结果,所以偶然性极大)
不过放到现在,4.0在有聚类模型的情况下效果还是优于3.0的
写在最后
未经允许,禁止转载到国内网站,包括但不限于CSDN等