sovit3折腾实录与教程(2)Colab训练 推理
值得一提的是,即使你炼丹在Colab, 推理也依然需要在本地进行
折腾了一下,推理可以在Colab进行了
先给链接:
推理脚本(用我自己三脚猫功夫改的)
正片开始
打开上面的训练脚本
为了方便后续,建议保存一个副本到你的GoogleDrive
在你GoogleDrive根目录创建一个名为dataset的文件夹
把说话人的数据压缩成zip传到dataset里面
注意是整个文件夹,而不是直接把wav打压缩
请使用zip,避免出现奇奇怪怪的错误
然后在Colab里从上到下点执行就可以,真的很简单
需要改的是“从谷歌云盘加载打包好的数据集进行预处理”这步
把DATASEINAME改成你说话人的名字
然后到训练,如果你是第一次并且选的48k的分支,请按照下面这么设置
一直到开始训练,等就好了,比本地简单不知道多少倍
再次训练
如果你的GPU到限额了啊 或者要关闭网页了,过了一段时间想重新回来炼丹的话
从“已经预处理过数据集的话,就可以跳过预处理部分 直接从云盘解压处理过的数据 以及配置文件”这步开始
当然前面Clone库该是需要的…
等待模型收敛
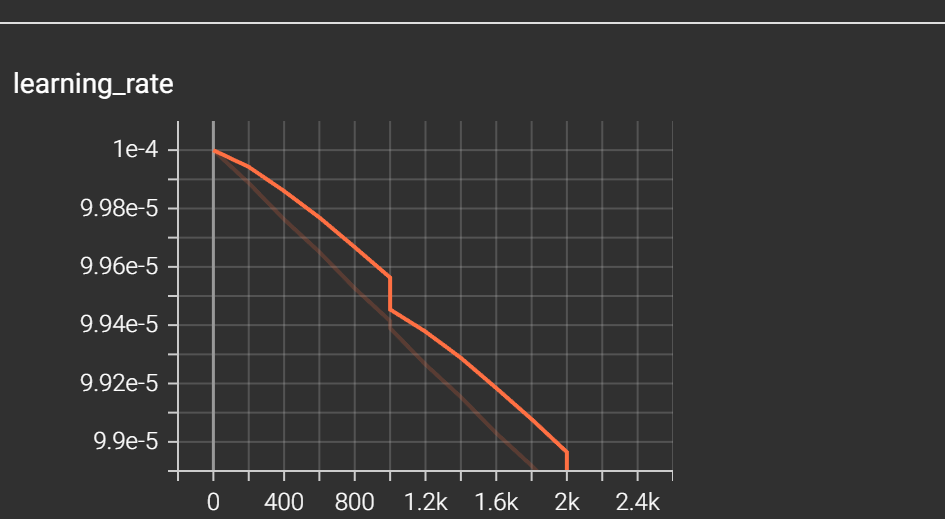
看你的TensorBoard,主要看learning_rate和loss最后面三个图表,也就是
g/kl g/mel g/total
learning_rate不断下降,且下降幅度放缓
g/kl g/mel g/total不断下降,且几乎与X轴平行,下降放缓
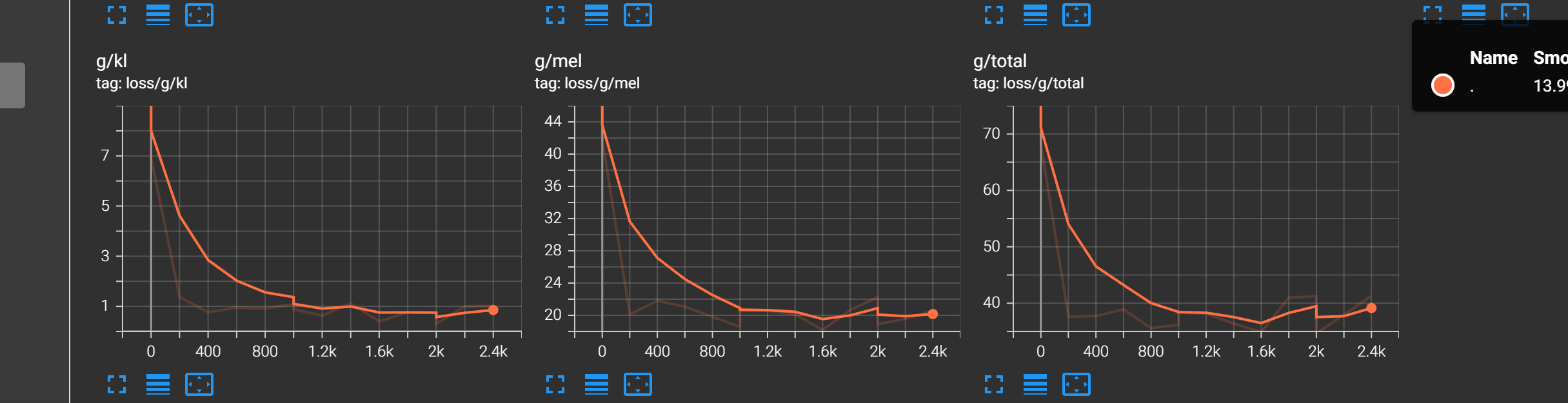
就代表模型基本收敛了,这个时候再训练下去可能会过拟合,模型会废
推理
如果模型收敛了,就可以推理了
这里分两个方法
Colab云端推理
推理脚本(用我自己三脚猫功夫改的)
保存笔记后,手动把你要转换的wav放到云端的/content/so-vits-svc/raw里面
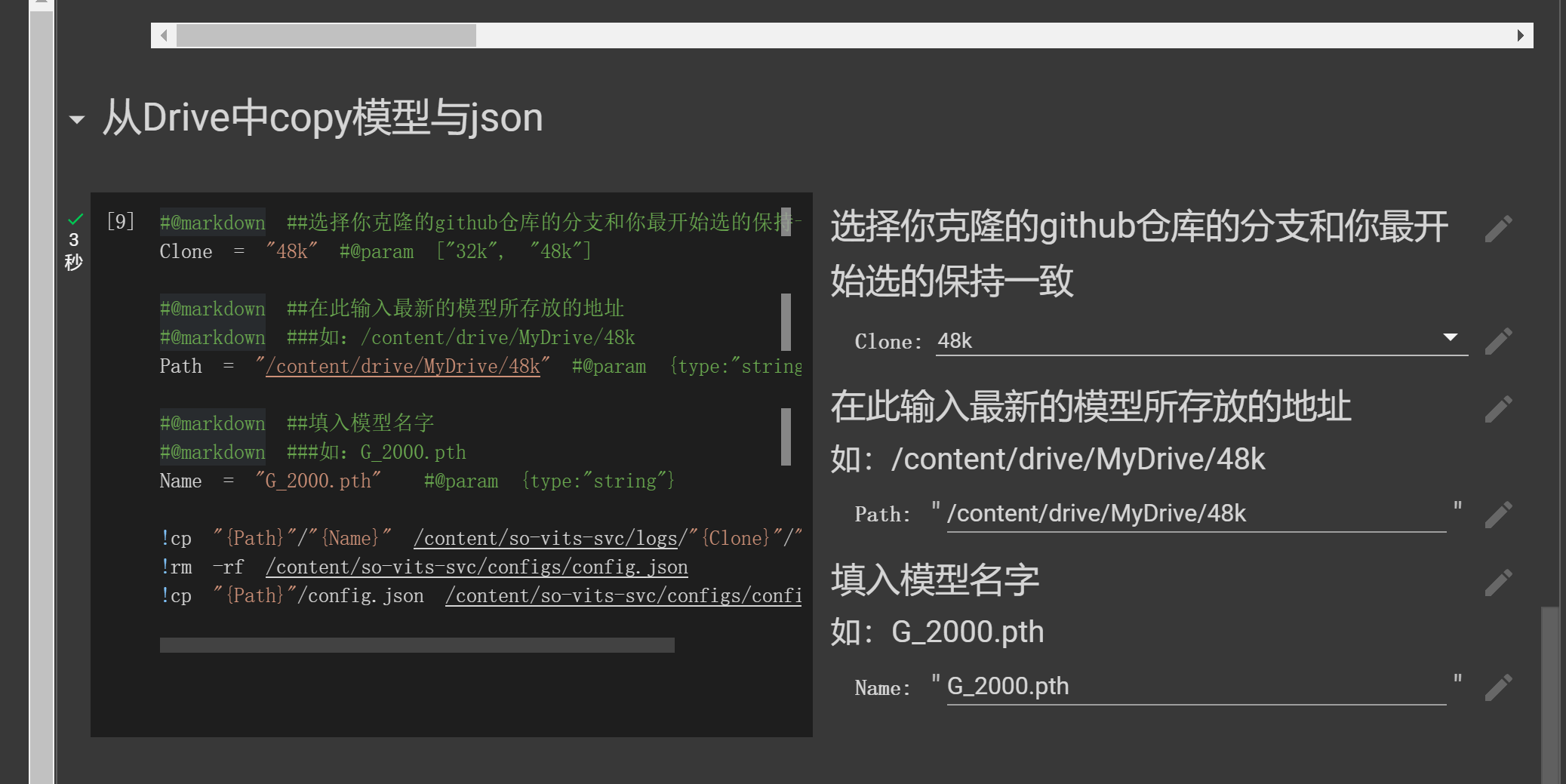
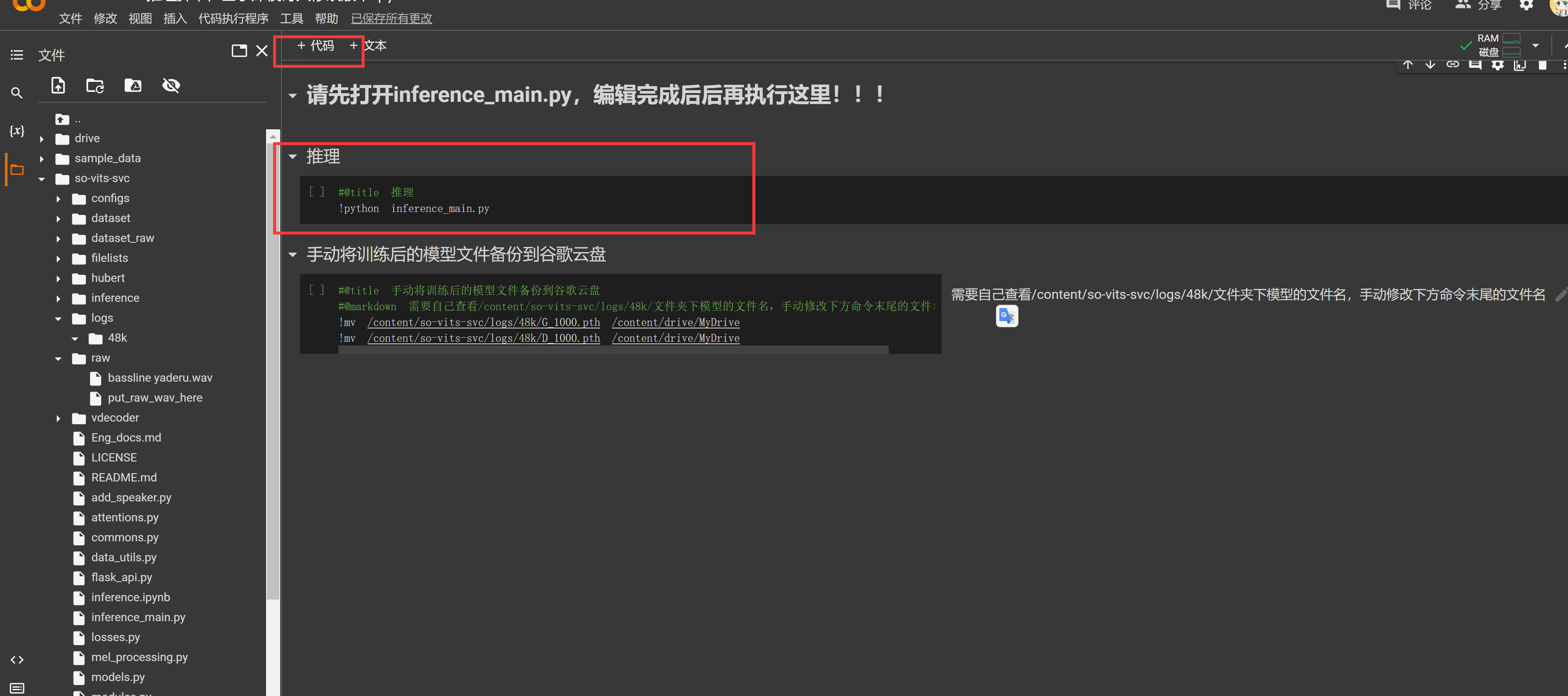
填一下“从Drive中copy模型与json”从上到下执行就可以了
如果你不需要我的三脚猫功夫,可以手动改
这里说一下要点:
在Colab中,系统命令前需要加一个!(半角)
推理依然需要必要模型
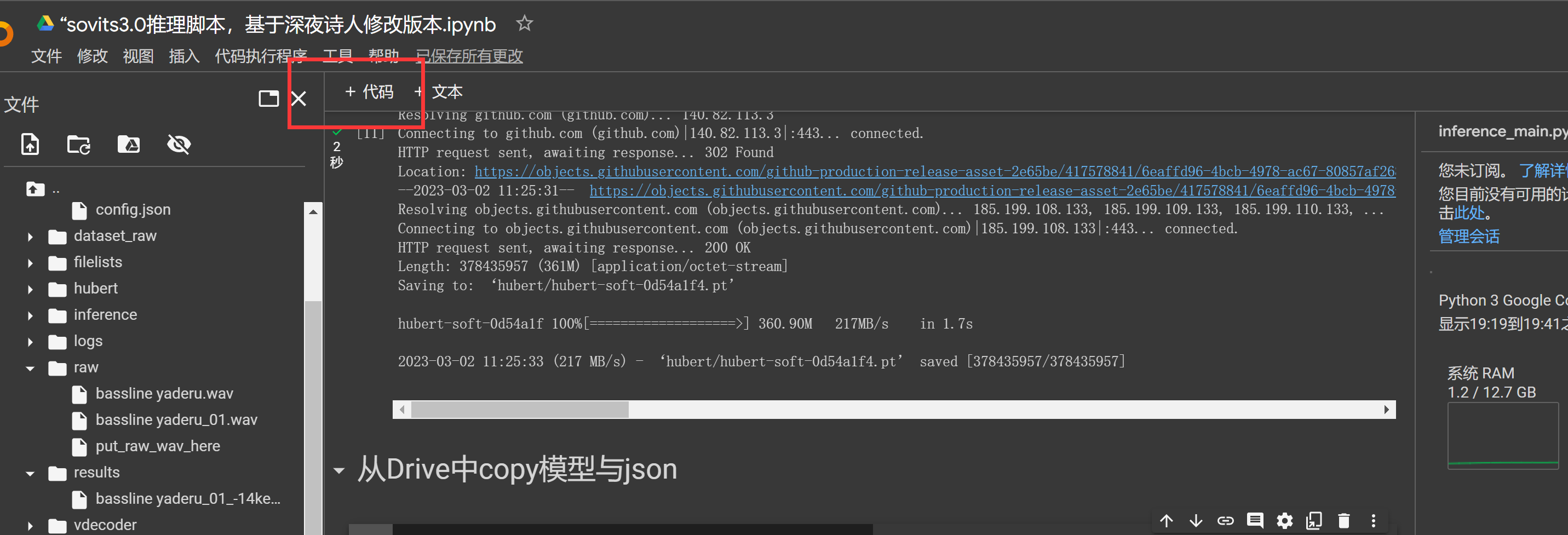
!wget -P hubert/ https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt
Drive云盘在挂载后地址为: /content/drive/MyDrive/
下面是详细的
加一个代码
在代码框中,你需要多安装一个依赖
!pip install scikit-maad
然后你可以选择手动把模型和config传上去,但这显然不如把Drive挂载后复制:
from google.colab import drive
drive.mount('/content/drive')
注意:推理所需要的是G_开头的模型,而不是D_开头的
大概是这样的:
!cp 你最新模型在挂载后的路径 /content/so-vits-svc/logs/48k/模型名字.pth
!rm -rf /content/so-vits-svc/configs/config.json
!cp 你模型config.json的路径 /content/so-vits-svc/configs/config.json
举个例子:
!cp /content/drive/MyDrive/48k/G_2000.pth /content/so-vits-svc/logs/48k/G_2000.pth
!rm -rf /content/so-vits-svc/configs/config.json
!cp /content/drive/MyDrive/48k/config.json /content/so-vits-svc/configs/config.json
以上为48k分支(也就是main分支),如果你选择32k,那应该是这样
!cp 你最新模型在挂载后的路径 /content/so-vits-svc/logs/32k/模型名字.pth
!rm -rf /content/so-vits-svc-32k/configs/config.json
!cp 你模型config.json的路径 /content/so-vits-svc-32k/configs/config.json
如果你是Colab Pro可以打开命令行,我不行所以我只能改笔记
接下来手动打开inference_main.py并修改
依然是重点改model_path,clean_names,trans,spk_list这几个
model_path改成你训练出最新模型的路径
clean_names改为你raw文件夹中放的wav的文件名,无需.wav结尾
trans为变调,根据实际来调,男模型唱女声大概需要-12~-16
spk_lisk为你说话人的名字,可以支持多个,用半角逗号隔开
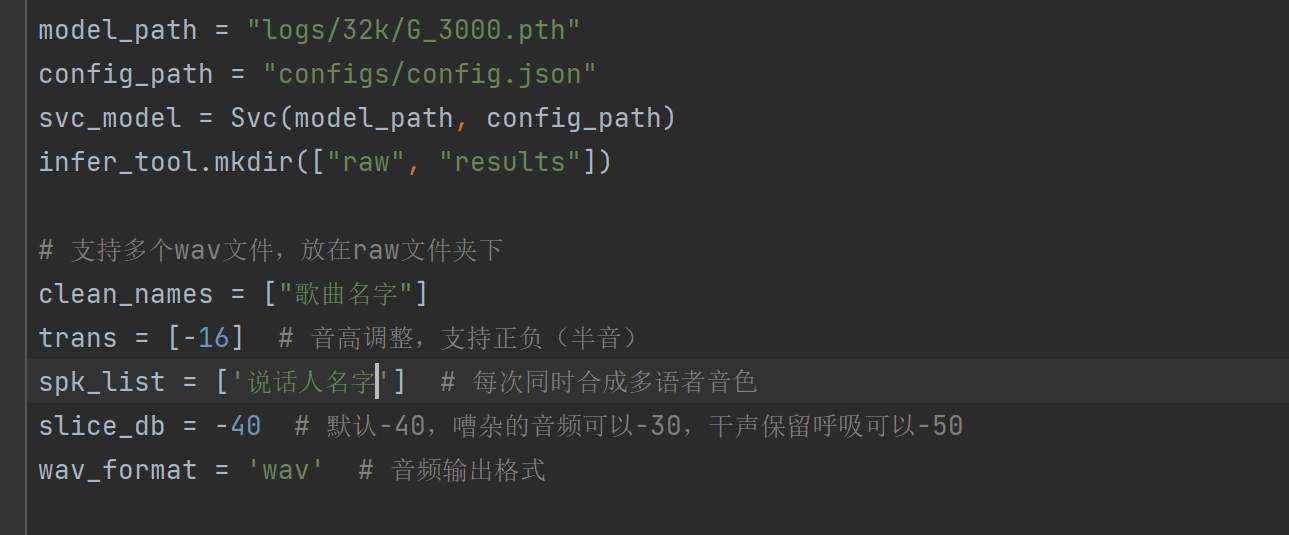
偷懒了,直接复制上一篇的过来
改完之后,加一个代码并运行
!python inference_main.py
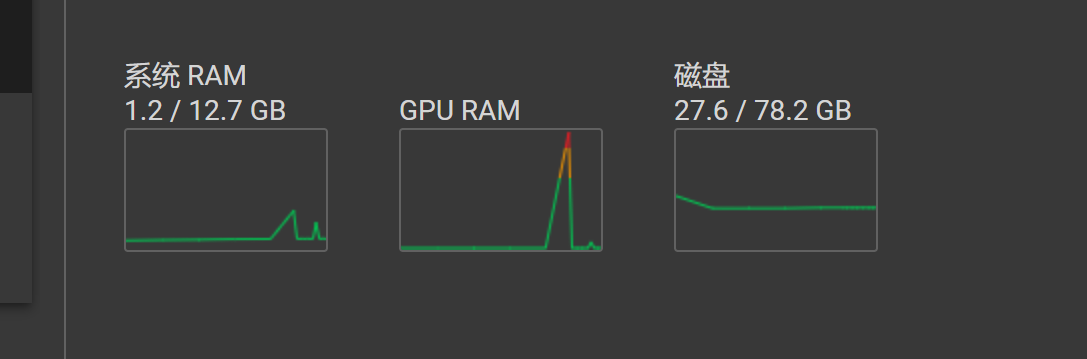
值得一提的是…即使Colab给了15GB大显存,如果你直接把一首歌不裁剪丢进去也丝毫不妨碍他炸显存
成功了就把results里的成果下载下来就好了
本地推理
首先,像上一篇一样配好环境 (这一句话足够折腾几个小时)
然后把Colab里出来的G_开头的.pth模型下载下来,放到你本地的logs/32k或者logs/48k文件夹中
把Colab上的configs/config.json放到和你本地一样的位置,也就是.../configs/config.json中
然后接下来与上一篇基本相同,不细说了
写在最后
未经允许,禁止转载到国内网站,包括但不限于CSDN等